
第十二章 蛋白质的生物合成及转运 蛋白质的生物合成在细胞代谢中占有十分重要的地位。目前己经完全清楚,贮存遗传 信息的DNA并不是蛋白质合成的直接模板,DNA上的遗传信息需要通过转录传递给 mRNA。mRNA才是蛋白质合成的直接模板。mRNA是由4种核苷酸构成的多核苷酸,而 蛋白质是由20种左右的氨基酸构成的多肽,它们之间遗传信息的传递与从一种语言翻译成 另一种语言时的情形相似。所以人们称以mRNA为模板合成蛋白质的过程为翻译或转译 (translation)o 翻译的过程十分复杂,几乎涉及到细胞内所有种类的RNA和几十种蛋白质因子。蛋 白质合成的场所是核糖体,合成的原料是氨基酸,反应所需能量由AP和GTP提供。蛋 白质合成的早期研究工作都是用大肠杆菌的无细胞体系进行的,所以对大肠杆菌的蛋白质 合成机理了解最多。真核细胞蛋白质合成的机理与大肠杆菌的有许多相似之处。 第一节遗传密码 任何一种天然多肽都有其特定的严格的氨基酸序列。有机界拥有100~10种不同的 蛋白质,构成数目这么庞大的不同的多肽的单体却只有20种氨基酸。氨基酸在多肽中的不 同排列次序是蛋白质多样性的基础。目前己经清楚,多肽上氨基酸的排列次序最终是由 DNA上核苷酸的排列次序决定的,而直接决定多肽上氨基酸次序的却是mRNA。不论是 DNA还是mRNA,基本上都由4种核苷酸构成。这4种核苷酸如何编制成遗传密码,遗 传密码又如何被翻译成20种氨基酸组成的多肚,这就是蛋白质生物合成中的遗传密码的翻 译问题。 一、密码单位 用数学方法推算,如果mRNA分子中的一种碱基编码一种氨基酸,那么4种碱基只能 决定4种氨基酸,而蛋白质分子中的氨基酸有20种,所以显然是不行的。如果由mRNA 分子中每2个相邻的碱基编码一种氨基酸,也只能编码42-16种氨基酸,仍然不够。如果 采用每3个相邻的碱基为一个氨基酸编码,则4=64,可以满足20种氨基酸编码的需要。 所以这种编码方式的可能性最大。应用生物化学和遗传学的研究技术,已经充分证明了是 293
293 第十二章 蛋白质的生物合成及转运 蛋白质的生物合成在细胞代谢中占有十分重要的地位。目前已经完全清楚,贮存遗传 信息的 DNA 并不是蛋白质合成的直接模板,DNA 上的遗传信息需要通过转录传递给 mRNA。mRNA 才是蛋白质合成的直接模板。mRNA 是由 4 种核苷酸构成的多核苷酸,而 蛋白质是由 20 种左右的氨基酸构成的多肽,它们之间遗传信息的传递与从一种语言翻译成 另一种语言时的情形相似。所以人们称以 mRNA 为模板合成蛋白质的过程为翻译或转译 (translation)。 翻译的过程十分复杂,几乎涉及到细胞内所有种类的 RNA 和几十种蛋白质因子。蛋 白质合成的场所是核糖体,合成的原料是氨基酸,反应所需能量由 ATP和 GTP提供。 蛋 白质合成的早期研究工作都是用大肠杆菌的无细胞体系进行的,所以对大肠杆菌的蛋白质 合成机理了解最多。真核细胞蛋白质合成的机理与大肠杆菌的有许多相似之处。 第一节 遗传密码 任何一种天然多肽都有其特定的严格的氨基酸序列。有机界拥有 1010~1011 种不同的 蛋白质,构成数目这么庞大的不同的多肽的单体却只有 20种氨基酸。氨基酸在多肽中的不 同排列次序是蛋白质多样性的基础。目前已经清楚,多肽上氨基酸的排列次序最终是由 DNA 上核苷酸的排列次序决定的,而直接决定多肽上氨基酸次序的却是 mRNA。不论是 DNA 还是 mRNA,基本上都由 4 种核苷酸构成。这 4 种核苷酸如何编制成遗传密码,遗 传密码又如何被翻译成 20 种氨基酸组成的多肽,这就是蛋白质生物合成中的遗传密码的翻 译问题。 一、密码单位 用数学方法推算,如果 mRNA 分子中的一种碱基编码一种氨基酸,那么 4 种碱基只能 决定 4 种氨基酸,而蛋白质分子中的氨基酸有 20 种,所以显然是不行的。如果由 mRNA 分子中每 2 个相邻的碱基编码一种氨基酸,也只能编码 4 2=16 种氨基酸,仍然不够。如果 采用每 3 个相邻的碱基为一个氨基酸编码,则 4 3=64,可以满足 20种氨基酸编码的需要。 所以这种编码方式的可能性最大。应用生物化学和遗传学的研究技术,已经充分证明了是
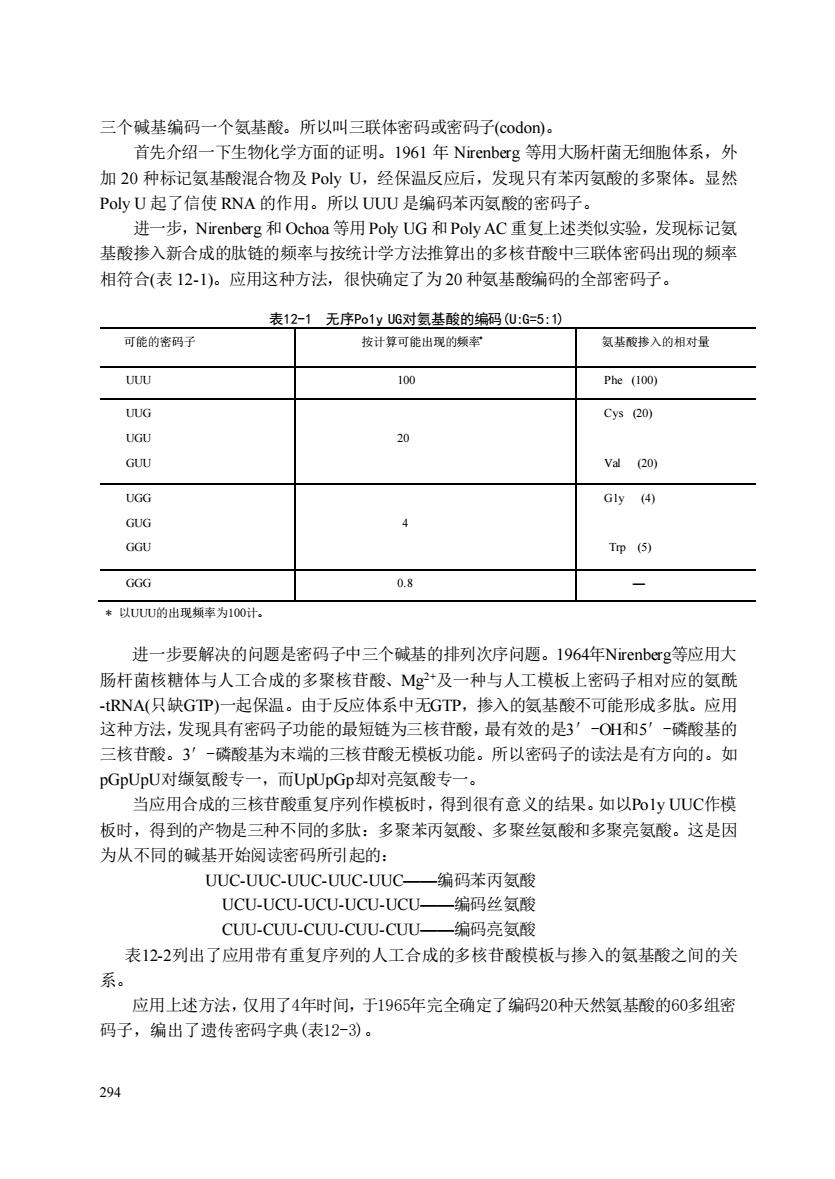
三个碱基编码一个氨基酸。所以叫三联体密码或密码子(codon))。 首先介绍一下生物化学方面的证明。1961年Nirenberg等用大肠杆菌无细胞体系,外 加20种标记氨基酸混合物及PyU,经保温反应后,发现只有苯丙氨酸的多聚体。显然 PoyU起了信使RNA的作用。所以UUU是编码苯丙氨酸的密码子。 进一步,Nirenberg和Ochoa等用PolyUG和Poly AC重复上述类似实验,发现标记氨 基酸掺入新合成的肤链的频率与按统计学方法推算出的多核苷酸中三联体密码出现的颜率 相符合(表12-1)。应用这种方法,很快确定了为20种氨基酸编码的全部密码子。 表12-1无序Po1yUG对氨基酸的编码U:G=5:1) 可能的密码子 按计算可能出现的频率 氨基酸摻入的相对量 UUU Phe (100) UUG Cys (20) 20 GUU va(20) UGG Gy④ GUG GGU Trp (5) GGG 08 *以UUU的出现频率为100计. 进一步要解决的问题是密码子中三个碱基的排列次序问题。1964年Nirenberg等应用大 肠杆菌核糖体与人工合成的多聚核苷酸、Mg2+及一种与人工模板上密码子相对应的氨酰 -RNA(只缺GP)一起保温。由于反应体系中无GTP,掺入的奥基酸不可能形成多肽。应用 这种方法,发现具有密码子功能的最短链为三核苷酸,最有效的是3'0H和5'-磷酸基的 三核苷酸。3'一磷酸基为末端的三核苷酸无模板功能。所以密码子的读法是有方向的。如 pGpUpU对缬氨酸专一,而UpUpGp却对亮氨酸专一。 当应用合成的三核苷酸重复序列作模板时,得到很有意义的结果。如以Po1yUUC作模 板时,得到的产物是三种不同的多肽:多聚苯丙氨酸、多聚丝氨酸和多聚亮氨酸。这是因 为从不同的碱基开始阅读密码所引起的: UUC-UUC-UUC-UUC-UUC- 编码苯丙氨酸 UCU-UCU-UCU-UCU-UCU- -编码丝氨酸 CUU-CUU-CUU-CUU-CUU一编码亮氨酸 表122列出了应用带有重复序列的人工合成的多核苷酸模板与掺入的氨基酸之间的关 系。 应用上述方法,仅用了4年时间,于1965年完全确定了编码20种天然氨基酸的60多组密 码子,编出了遗传密码字典(表12-)。 294
294 三个碱基编码一个氨基酸。所以叫三联体密码或密码子(codon)。 首先介绍一下生物化学方面的证明。1961 年 Nirenberg 等用大肠杆菌无细胞体系,外 加 20 种标记氨基酸混合物及 Poly U,经保温反应后,发现只有苯丙氨酸的多聚体。显然 Poly U 起了信使 RNA 的作用。所以 UUU 是编码苯丙氨酸的密码子。 进一步,Nirenberg 和 Ochoa 等用Poly UG 和Poly AC 重复上述类似实验,发现标记氨 基酸掺入新合成的肽链的频率与按统计学方法推算出的多核苷酸中三联体密码出现的频率 相符合(表 12-1)。应用这种方法,很快确定了为 20 种氨基酸编码的全部密码子。 表12-1 无序Po1y UG对氨基酸的编码(U:G=5:1) 可能的密码子 按计算可能出现的频率* 氨基酸掺入的相对量 UUU 100 Phe (100) UUG UGU GUU 20 Cys (20) Val (20) UGG GUG GGU 4 G1y (4) Trp (5) GGG 0.8 — * 以UUU的出现频率为100计。 进一步要解决的问题是密码子中三个碱基的排列次序问题。1964年Nirenberg等应用大 肠杆菌核糖体与人工合成的多聚核苷酸、Mg2+及一种与人工模板上密码子相对应的氨酰 -tRNA(只缺GTP)一起保温。由于反应体系中无GTP,掺入的氨基酸不可能形成多肽。应用 这种方法,发现具有密码子功能的最短链为三核苷酸,最有效的是3′-OH和5′-磷酸基的 三核苷酸。3′-磷酸基为末端的三核苷酸无模板功能。所以密码子的读法是有方向的。如 pGpUpU对缬氨酸专一,而UpUpGp却对亮氨酸专一。 当应用合成的三核苷酸重复序列作模板时,得到很有意义的结果。如以Po1y UUC作模 板时,得到的产物是三种不同的多肽:多聚苯丙氨酸、多聚丝氨酸和多聚亮氨酸。这是因 为从不同的碱基开始阅读密码所引起的: UUC-UUC-UUC-UUC-UUC——编码苯丙氨酸 UCU-UCU-UCU-UCU-UCU——编码丝氨酸 CUU-CUU-CUU-CUU-CUU——编码亮氨酸 表12-2列出了应用带有重复序列的人工合成的多核苷酸模板与掺入的氨基酸之间的关 系。 应用上述方法,仅用了4年时间,于1965年完全确定了编码20种天然氨基酸的60多组密 码子,编出了遗传密码字典(表12-3)
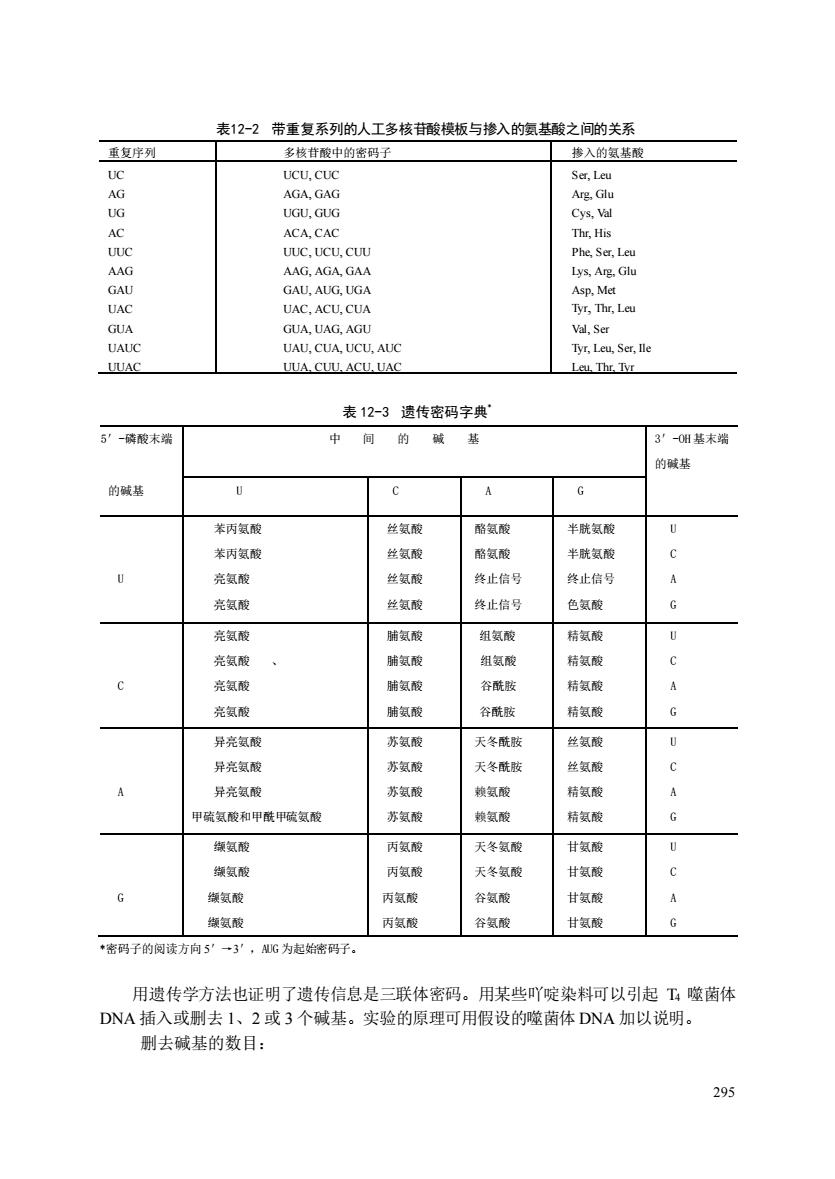
表12-2带重复系列的人工多核昔酸模板与掺入的氨酸之间的关系 重复序列 多核苷酸中的密码子 掺入的氨基酸 UCU,CU Ser,Leu UUC.UCU.CUU Phe Ser Le AAG AAG AGA GAA Lys.Arg.Glu GAU GAU AUG UGA Asp.Met UAC UAC.ACU.CUA Tyr.Thr.Leu GUA GUA UAG AGU Val Ser UAUC UAU,CUA,UCU,AUC Tyr,Leu,Ser,lle UUAC UUA.CUU.ACU.UAC Leu,Thr,Tvr 表12-3遗传密码字典 5’-磷酸末瑞 中间的碱基 3'-0附基末端 的碱基 的碱基 6 A 6 苯丙氨酸 位氨酸 酪氨酸 半胱氨酸 苯丙氨酸 丝氨酸 酪氨酸 半胱氨酸 亮氨酸 华氨酸 终止信号 终止信写 亮氨酸 丝氨酸 终止信号 色氨酸 尧氨酸 肺氨酸 组氨酸 精氨酸 亮氨酸 脯氨酸 组氨酸 精氨酸 亮氨酸 脯氨酸 谷酰影 精氨酸 尧氨酸 肺氨酸 谷酰 精氨酸 异亮氨酸 苏氨酸 天冬酰胺 丝氨 异亮氨酸 苏氨酸 天冬酰胺 丝氨酸 异亮氨酸 苏氨酸 赖氨酸 精氨酸 甲货氨酸和甲酰甲氨酸 苏氨酸 赖氨酸 精氨酸 鞭氨酸 丙氨酸 天冬氨酸 甘氨酸 缬氨酸 丙氨酸 天冬氨酸 甘氨酸 缬氨酸 丙氨酸 谷氨酸 甘氨酸 傲氨酸 丙氨酸 谷氨酸 甘氨酸 密码子的阅读方向5”一3',G为起始等码子。 用遗传学方法也证明了遗传信息是三联体密码。用某些吖啶染料可以引起T噬菌体 DNA插入或删去1、2或3个碱基。实验的原理可用假设的噬菌体DNA加以说明。 删去碱基的数目: 多
295 表12-2 带重复系列的人工多核苷酸模板与掺入的氨基酸之间的关系 表 12-3 遗传密码字典* *密码子的阅读方向 5′→3′,AUG 为起始密码子。 用遗传学方法也证明了遗传信息是三联体密码。用某些吖啶染料可以引起 T4 噬菌体 DNA 插入或删去 1、2 或 3 个碱基。实验的原理可用假设的噬菌体 DNA 加以说明。 删去碱基的数目: 重复序列 多核苷酸中的密码子 掺入的氨基酸 UC AG UG AC UUC AAG GAU UAC GUA UAUC UUAC UCU, CUC AGA, GAG UGU, GUG ACA, CAC UUC, UCU, CUU AAG, AGA, GAA GAU, AUG, UGA UAC, ACU, CUA GUA, UAG, AGU UAU, CUA, UCU, AUC UUA, CUU, ACU, UAC Ser, Leu Arg, Glu Cys, Val Thr, His Phe, Ser, Leu Lys, Arg, Glu Asp, Met Tyr, Thr, Leu Val, Ser Tyr, Leu, Ser, Ile Leu, Thr, Tyr 5′-磷酸末端 中 间 的 碱 基 3′-OH 基末端 的碱基 的碱基 U C A G U 苯丙氨酸 苯丙氨酸 亮氨酸 亮氨酸 丝氨酸 丝氨酸 丝氨酸 丝氨酸 酪氨酸 酪氨酸 终止信号 终止信号 半胱氨酸 半胱氨酸 终止信号 色氨酸 U C A G C 亮氨酸 亮氨酸 、 亮氨酸 亮氨酸 脯氨酸 脯氨酸 脯氨酸 脯氨酸 组氨酸 组氨酸 谷酰胺 谷酰胺 精氨酸 精氨酸 精氨酸 精氨酸 U C A G A 异亮氨酸 异亮氨酸 异亮氨酸 甲硫氨酸和甲酰甲硫氨酸 苏氨酸 苏氨酸 苏氨酸 苏氨酸 天冬酰胺 天冬酰胺 赖氨酸 赖氨酸 丝氨酸 丝氨酸 精氨酸 精氨酸 U C A G G 缬氨酸 缬氨酸 缬氨酸 缬氨酸 丙氨酸 丙氨酸 丙氨酸 丙氨酸 天冬氨酸 天冬氨酸 谷氨酸 谷氨酸 甘氨酸 甘氨酸 甘氨酸 甘氨酸 U C A G

CAT CIC CAIC AIC AICAIC AIC CAT CTC ACA TCA TCATCA TCA 3 CAT CTC ACA TAT CAT CAT CAT A c 当删去一个碱基A时,从这一点以后的密码就发生了差错。刷去两个碱基时,情形也 如此。但是删去三个碱基时,情况就不同了。最先也形城几组错误的密码子,但以后又恢 复正常。前面两类突变往往使基因产物全部失去活力,而第三种突变类型使基因产物仍具 有一定活力。这只能用遗传密码是三联体这个事实来加以解释。 二、遗传密码的基本特性 1.密码无标点符号即两个密码子之间没有任何起标点符号作用的密码子加以隔开 因此,要正确阅读密码必须按一定的读码框架从一个正确的起点开始,一个不漏地挨着读 下去,直至碰到终止信号。若插入或删去一个碱基,就会使这以后的读码发生错误,这称 为移码。由移码引起的突变称为移码突变。 2.一般情形下遗传密码不重叠假设mRNA上的核苷酸序列为ABCDEFGH山KL 按不重叠规则读码时应读为ABC DEF GHI JKL等,每三个碱基编码一个氨基酸,碱基 的使用不发生重复: ABC DEF GIΨKL .aa1.a2.aa5.aa4. 如果按完全重叠规则读码,则应该是ABC编码aa,BCD编码a,CDE编码aas,。 目前已经证明,在绝大多数生物中,读码规则是不重叠的。 3.密码的简并性(Clegeneracy)大多数氨基酸都可以具有几组不同的密码子,如UUA、 UUG,CUU、CUC、CUA及CUG6组密码子都编码亮氨酸。这一现象称为密码的简并。可 以编码相同氨基酸的密码子称为同义密码子(synonymcodon)。只有色氨酸及甲硫氨酸只有 一个密码子(表12-4)。密码的简并性在生物物种的稳定性上具有一定意义。 码子中室 三位碱基具有较小的专 密码的简并性往往只涉及第三位碱基。如 丙氨酸有4组密码子:GCU、GCC、GCA、GCG,前两位碱基都相同,均为GC,只是第三 位不相同。已经证明,密码子的专一性主要由前两位碱基决定,第三位碱基的重要性不大。 Ci©k对第三位碱基的这一特性给予一个专门的术语,称为“摆动性”。当第三位碱基发生 突变时,仍能翻译出正确的氨基酸来,从而使合成的多肽仍具有生物学活力。特别应该指 出的是:RNA的反密码子中,除A、U、G、C4种碱基外,还经常出现次黄嘌。次黄嘌 296
296 0 CAT CAT CAT CAT CAT CAT CAT 1 CAT CTC ATC ATC ATC ATC ATC ↓ A 2 CAT CTC ACA TCA TCA TCA TCA ↓ ↓ A T 3 CAT CTC ACA TAT CAT CAT CAT ↓ ↓ ↓ A T C 当删去一个碱基A时,从这一点以后的密码就发生了差错。删去两个碱基时,情形也 如此。但是删去三个碱基时,情况就不同了。最先也形成几组错误的密码子,但以后又恢 复正常。前面两类突变往往使基因产物全部失去活力,而第三种突变类型使基因产物仍具 有一定活力。这只能用遗传密码是三联体这个事实来加以解释。 二、遗传密码的基本特性 1.密码无标点符号 即两个密码子之间没有任何起标点符号作用的密码子加以隔开, 因此,要正确阅读密码必须按一定的读码框架从一个正确的起点开始,一个不漏地挨着读 下去,直至碰到终止信号。若插入或删去一个碱基,就会使这以后的读码发生错误,这称 为移码。由移码引起的突变称为移码突变。 2.一般情形下遗传密码不重叠 假设mRNA上的核苷酸序列为ABCDEFGHIJKL., 按不重叠规则读码时应读为ABC DEF GHI JKL等,每三个碱基编码一个氨基酸,碱基 的使用不发生重复: ABC DEF GHI JKL .aa1. .aa2.aa3.aa4. 如果按完全重叠规则读码,则应该是ABC编码aa1,BCD编码aa2,CDE编码aa3,.。 目前已经证明,在绝大多数生物中,读码规则是不重叠的。 3.密码的简并性(Clegeneracy) 大多数氨基酸都可以具有几组不同的密码子,如UUA、 UUG,CUU、CUC、CUA及CUG6组密码子都编码亮氨酸。这一现象称为密码的简并。可 以编码相同氨基酸的密码子称为同义密码子(synonymcodon)。只有色氨酸及甲硫氨酸只有 一个密码子(表12-4)。密码的简并性在生物物种的稳定性上具有一定意义。 4.密码子中第三位碱基具有较小的专一性 密码的简并性往往只涉及第三位碱基。如 丙氨酸有4组密码子:GCU、GCC、GCA、GCG,前两位碱基都相同,均为GC,只是第三 位不相同。已经证明,密码子的专一性主要由前两位碱基决定,第三位碱基的重要性不大。 Crick对第三位碱基的这一特性给予一个专门的术语,称为“摆动性”。当第三位碱基发生 突变时,仍能翻译出正确的氨基酸来,从而使合成的多肽仍具有生物学活力。特别应该指 出的是:tRNA的反密码子中,除A、U、G、C4种碱基外,还经常出现次黄嘌呤I。次黄嘌
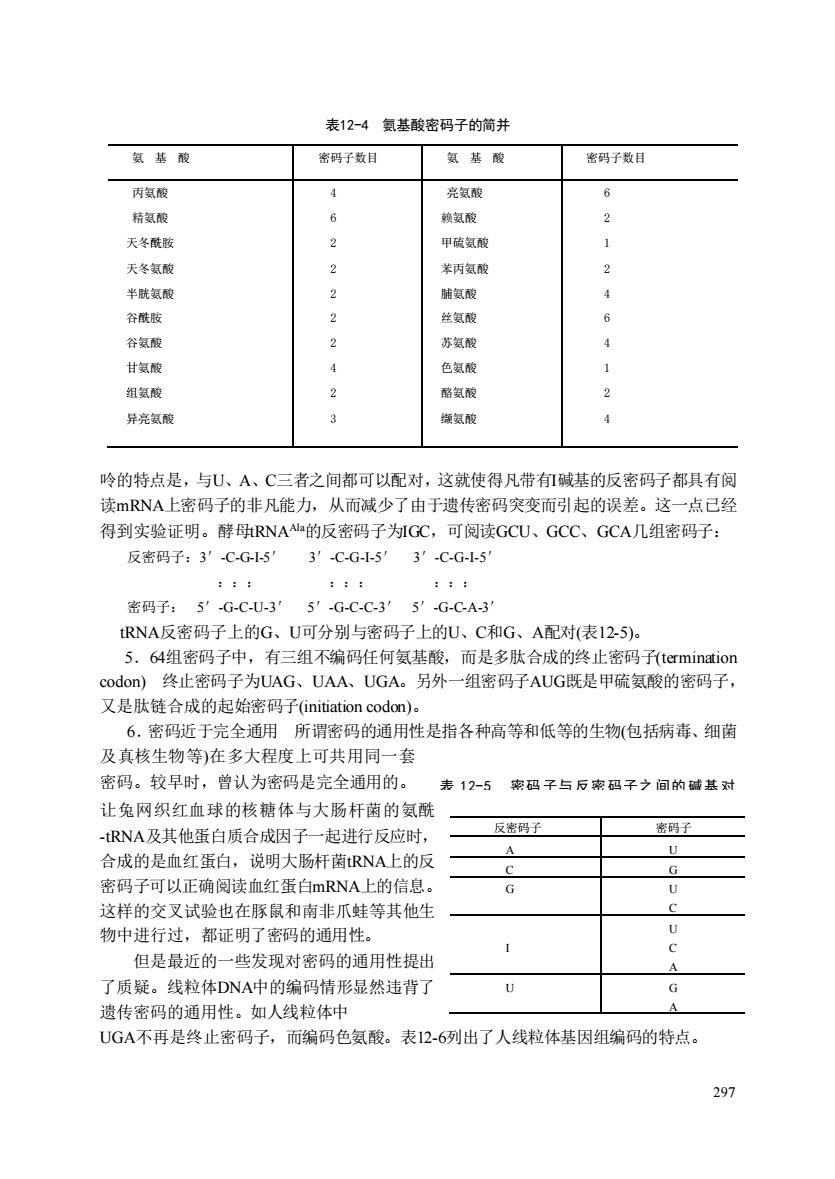
表12-4氨基酸密码子的简并 氨基酸 密码子数目 氨培酸 密码子数目 丙氨酸 亮氨酸 结氨酸 赖氨酸 天冬酰 2 甲破氨酸 天冬氨的 2 装丙氨酸 半胱氨面 2 肺氨酸 谷酰肢 性氨酸 谷氨酸 苏氨酸 甘氨板 色氨酸 组氨酸 酪氨酯 2 异亮氯酸 城氨酸 吟的特点是,与U、A、C三者之间都可以配对,这就使得凡带们碱基的反密码子都具有阅 读mRNA上密码子的非凡能力,从而减少了由于遗传密码突变而引起的误差。这一点己经 得到实验证明。酵马RNA的反密码子为GC,可阅读GCU、GCC、GCA几组密码子: 反密码子:3'CG5 3′-C-G-5'3'-C-G-5 密码子:5'-G-C-U-3'5'-G-C-C-3′5'-G-C-A-3 tRNA反密码子上的G、U可分别与密码子上的U、C和G、A配对(表12-5)。 5.64组码子中,有三组不编码任何氨基酸,而是多肽合成的终止码子termination odOn终止密码子为UAG、UAA、UGA。另外一组密码子AUG既是甲硫氨酸的密码子. 又是肽链合成的起始密码子((initiation codon). 6.密码近于完全通用所谓密码的通用性是指各种高等和低等的生物(包括病毒、细菌 及真核生物等)在多大程度上可共用同一套 密码。较早时,曾认为密码是完全通用的。 表12-5 码子与后索码子之间的碱基对 让兔网织红血球的核糖体与大肠杆菌的氨酰 -RNA及其他蛋白质合成因子一起进行反应时 反码子 密码子 合成的是血红蛋白,说明大肠杆菌RNA上的反 密码子可以正确阅读血红蛋白mRNA上的信息, 这样的交叉试验也在豚鼠和南非爪蛙等其他生 物中进行过,都证明了密码的通用性, 但是最近的一些发现对密码的通用性提出 了质疑。线粒体DNA中的编码情形显然违背了 U 遗传密码的诵用性。如人线粒体中 UG4不再是终止密码子,而编码色氨酸。表12-6列出了人线粒体基因组编码的特点。 多
297 表12-4 氨基酸密码子的简并 呤的特点是,与U、A、C三者之间都可以配对,这就使得凡带有I碱基的反密码子都具有阅 读mRNA上密码子的非凡能力,从而减少了由于遗传密码突变而引起的误差。这一点已经 得到实验证明。酵母tRNAAla的反密码子为IGC,可阅读GCU、GCC、GCA几组密码子: 反密码子:3′-C-G-I-5′ 3′-C-G-I-5′ 3′-C-G-I-5′ ::: ::: ::: 密码子: 5′-G-C-U-3′ 5′-G-C-C-3′ 5′-G-C-A-3′ tRNA反密码子上的G、U可分别与密码子上的U、C和G、A配对(表12-5)。 5.64组密码子中,有三组不编码任何氨基酸,而是多肽合成的终止密码子(termination codon) 终止密码子为UAG、UAA、UGA。另外一组密码子AUG既是甲硫氨酸的密码子, 又是肽链合成的起始密码子(initiation codon)。 6.密码近于完全通用 所谓密码的通用性是指各种高等和低等的生物(包括病毒、细菌 及真核生物等)在多大程度上可共用同一套 密码。较早时,曾认为密码是完全通用的。 让兔网织红血球的核糖体与大肠杆菌的氨酰 -tRNA及其他蛋白质合成因子一起进行反应时, 合成的是血红蛋白,说明大肠杆菌tRNA上的反 密码子可以正确阅读血红蛋白mRNA上的信息。 这样的交叉试验也在豚鼠和南非爪蛙等其他生 物中进行过,都证明了密码的通用性。 但是最近的一些发现对密码的通用性提出 了质疑。线粒体DNA中的编码情形显然违背了 遗传密码的通用性。如人线粒体中 UGA不再是终止密码子,而编码色氨酸。表12-6列出了人线粒体基因组编码的特点。 氨 基 酸 密码子数目 氨 基 酸 密码子数目 丙氨酸 精氨酸 天冬酰胺 天冬氨酸 半胱氨酸 谷酰胺 谷氨酸 甘氨酸 组氨酸 异亮氨酸 4 6 2 2 2 2 2 4 2 3 亮氨酸 赖氨酸 甲硫氨酸 苯丙氨酸 脯氨酸 丝氨酸 苏氨酸 色氨酸 酪氨酸 缬氨酸 6 2 1 2 4 6 4 1 2 4 反密码子 密码子 A U C G G U C I U C A U G A 表 12-5 密码 子与 反密 码子之 间的 碱基 对